
SQL은 관계형 데이터베이스에서 널리 쓰이는 쿼리언어이다. SQL은 쿼리의 기능 뿐 아니라 데이터를 수정하는 DML(Data Manipulation Language)의 기능과 스키마를 정의하는 DDL(Data Definition Language)의 기능도 갖는다.
SQL도 다양한 버전이 있다. ANSI, SQL-92(SQL2, SQL:1992), SQL-99(SQL3, SQL:1999), SQL:2023 등이다. 이 글에서 다루는 것은 SQL-92이다.
6.1 Simple Queries in SQL
SELECT, FROM, WHERE을 가지고 기초적인 쿼리를 할 수 있다. 관계대수(relational algebra)로 치자면, SELECT는 사영(projection) 조건, WHERE은 선택(selection) 조건을 담당한다.
SELECT
- SELECT * FROM Movies WHERE year = 1990 and studioName = ‘Disney’;
AS로 alias를 지정할 수 있다.
- SELECT title AS name, length AS duration FROM…
연산을 하거나, 상수를 넣을 수도 있다.
- SELECT title AS name, length * 0.01667 AS lengthInHours, ‘hrs.’ AS inHours FROM …
WHERE
프로그래밍 언어처럼 다양한 조건문을 넣을 수 있다. 숫자 뿐 아니라 문자열도 연산 가능하다.
- 부등호: =, >, <, <>, …
- 산수: +, *, …
- 문자열: || (concatenation)
- 논리: AND, OR, NOT
- 패턴매칭: LIKE,
- s는 문자열, p는 패턴일때, s LIKE p로 표현한다.
- p에는 %와 _를 넣어 표현한다.
- %: 길이가 0 또는 1 이상의 문자열
- _: 딱 한글자
Values
- DATE: (키워드 DATE) + ‘yyyy-MM-dd’형태
- TIME: (키워드 TIME) + ‘HH:mm:ss’ 형태
- TIMESTAMP: (키워드 TIMESTAMP) + ‘yyyy-MM-dd HH:mm:ss’ 형태
- NULL
- 3가지 해석을 할 수 있다.
- 정말 값을 알수 없을때
- 값이 들어있는 것이 부적절할 때
- 값을 알 수 있는 권한이 없을 때
- 만약 이 NULL이 WHERE문 안에서 연산이 된다면, 다음을 따른다.
- *나 + 같은 산수 결과는 NULL이다.
- 나 = 같은 비교 결과는 BOOLEAN 타입인 UNKNOWN이다.
- 참고로, NULL이 상수로 쓰일 순 없다. x+3을 연산할때 x가 NULL일수는 있지만, NULL+3은 틀린 SQL 문법이다.
- 3가지 해석을 할 수 있다.
- UNKNOWN: 논리적으로 이해하면 된다.
- AND 연산
- (UNKNOWN) AND (TRUE)는 UNKNOWN이다. (순서가 달라져도)
- (UNKNOWN) AND (FALSE)는 FALSE이다. (순서가 달라져도)
- (UNKNOWN) AND (UNKNOWN)은 UNKNOWN이다.
- OR 연산
- (UNKNOWN) OR (TRUE)는 TRUE이다. (순서가 달라져도)
- (UNKNOWN) OR (FALSE)는 UNKNOWN이다. (순서가 달라져도)
- (UNKNOWN) OR (UNKNOWN)은 UNKNOWN이다.
- NOT 연산
- NOT (UNKNOWN)은 UNKNOWN이다.
- 만약 WHERE 문의 표현식 전체 결과가 UNKNOWN이면, 해당 튜플은 쿼리 결과에 포함되지 않는다.
- AND 연산
ORDER BY
ORDER BY는 순서를 정렬한다. FROM과 WHERE이 다 실행된 후, SELECT 직전에 연산된다. 디폴트는 오름차순(ASC)이다. 표현식이 들어갈수 있다.
- SELECT * FROM R ORDER BY A+B DESC;
6.2 Queries Involving More Then One Relation
두 개 이상의 릴레이션에 동시에 쿼리할 수 있다.

다행히, 이 경우는 Movies와 MovieExec 사이에 겹치는 이름의 속성이 없었다. 만약 있다면 명시적으로 구분해줘야 한다.
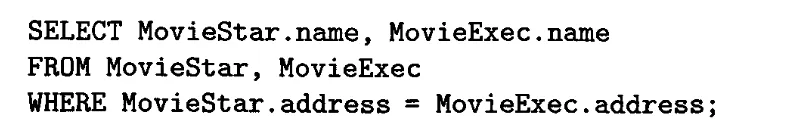
심지어는 릴레이션 안에서 서로 다른 튜플끼리 연산을 시킬수도 있다. Star1.name < Star2.name 절은 순서만 바뀐 두 튜플이 서로 다른 결과로 나오는 것을 막기 위해 존재한다.

서로 다른 SELECT-FROM-WHERE 쿼리 결과 간의 연산도 할 수 있다. 순서대로 교집합, 차집합, 합집합이다. 만약 왼편의 속성은 title, 오른편의 속성은 movieTitle이라면 movieTitle as title 로 alias해주어야 의도대로 동작할 것이다. 이때, 실행결과는 bags가 아닌 집합이다. 중복이 제거된다.
- (select-from-where) INTERSECT (select-from-where)
- (select-from-where) EXCEPT (select-from-where)
- (select-from-where) UNION (select-from-where)
6.3 Subqueries
앞서 쿼리의 결과를 하나의 릴레이션처럼 사용해서 INTERSECT같은 연산의 피연산자(operand)로 사용하는 예시를 보았다. (select-from-where)문을 괄호로 감싸면, 서브쿼리(subquery)로 사용가능하다. 서브쿼리의 결과가 무엇이냐에 따라, 3가지 사용방법이 있다.
1. 하나의 상수를 반환할 때

여기서 서브쿼리는 정확히 하나의 상수만을 반환해야한다. 만약 하나의 상수만을 반환했다면, 그 값으로 서브쿼리 전체를 치환하면 된다. 그러나 반환된 상수가 없거나 두개 이상이면 런타임 에러를 발생시킨다.
2. 컬럼 1개짜리 릴레이션을 반환할때
WHERE문 안에서 연산자와 함께 사용되며 BOOLEAN값을 반환할 수 있다. 서브쿼리 결과 R에 대한, 새로운 연산자들을 소개한다.
- EXISTS R: R이 비어있지 않으면 TRUE
- s IN R: s 라는 값이 R에 존재하면 TRUE
- s NOT IN R: s 라는 값이 R에 없으면 TRUE
- s > ALL R: 모든 R의 값이 s 보다 작으면 TRUE
- s > ANY R: 어떤 R의 값이 s보다 작으면 TRUE
- EXISTS, ALL, ANY는 NOT을 붙여서 부정할 수 있음
3. 컬럼 2개 이상의 릴레이션을 반환할때
앞서 (2)에서 말한 연산자 중 IN 을 사용할 수 있다. 대신 s와 R의 속성 개수가 맞아야 한다.
지금까지 알아본 서브쿼리들은 일단 쿼리를 실행한 후, 나온 결과를 부모 쿼리에 치환해두면 끝나는 것처럼 보였다. 그러나, 지금 소개할 “Correlated subquery”는 부모 쿼리의 검사하려는 튜플마다 매번 새롭게 연산해야하는 경우이다. 서브쿼리의 두번째에 등장한 title 앞에 Old. 를 붙여서 scope를 명시한 것을 주의해서 봐야 한다.

서브쿼리를 FROM 문에서 사용할 수도 있다. 반드시 alias를 해주어야 한다.

'개인 공부' 카테고리의 다른 글
| [데이터베이스 개론] 7. 인덱스 구조(Index Structures) (0) | 2025.06.16 |
|---|---|
| [데이터베이스 개론] 6. 2차 저장소 관리(Secondary Storage Management) (1) | 2025.06.16 |
| [데이터베이스 개론] 4. 대수적/논리적 쿼리 언어(Algebraic and Logical Query Language) (0) | 2025.04.22 |
| [데이터베이스 개론] 3. 고급 데이터베이스 모델(High-Level Database Model) (0) | 2025.04.22 |
| [데이터베이스 개론] 2. 관계형 데이터베이스 설계(Design Theory for Relational Databases) (0) | 2025.04.22 |