데이터베이스는 항상 디스크 등의 대용량의 데이터를 저장하는 2차 저장소를 갖습니다. 이 챕터에서는 전통적인 컴퓨터가 어떻게 스토리지를 관리하는지 요약합니다. 또, 릴레이션의 튜플들을 어떻게 저장하는지 다룹니다.
13.1 메모리 계층(The Memory Hierarchy)
컴퓨터 속 메모리 계층을 시작으로 챕터를 시작해봅시다. 메모리를 저장하는 부품들은 7종류로 나뉩니다. 크기와 접근 속도가 모두 다르며, 크기가 작을수록 접근속도는 빠르고, 바이트 당 가격도 올라갑니다.
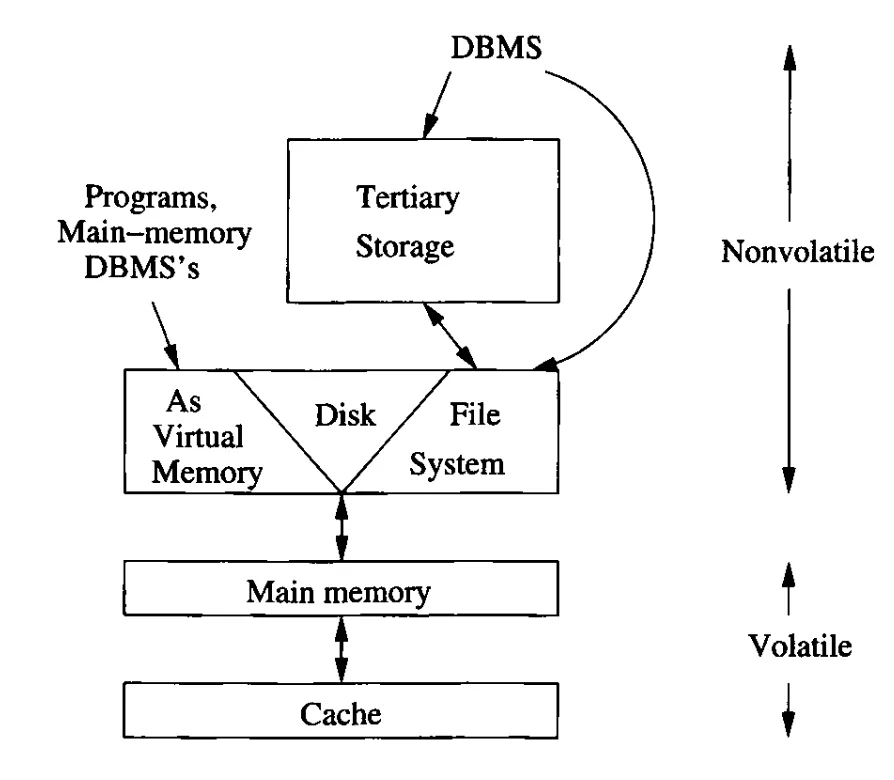
- 캐시(Cache): 내장 캐시(On-board cache)는 프로세서 그 자체 안에 포함되어 있고, 추가적인 level-2 캐시는 다른 칩에 포함됩니다. 프로세서가 요구하는 데이터는 메인 메모리에서 캐시로 옮겨져서, 몇 나노초 안에 데이터를 프로세서에 제공합니다.
- 메인 메모리(Main memory): 명령어 실행 및 데이터 수정 등에 필요한 정보들은 메인 메모리에 상주합니다. 메인 메모리에서 프로세서나 캐시로 데이터를 옮기는 데에는 10~100 나노초가 필요합니다.
- 2차 저장소(Secondary Storage): 보통 자기 디스크를 의미한다. 디스크에서 메인 메모리로 데이터를 옮기는 데에는 10 밀리초 정도가 소요된다. 대신, 한번에 많은 바이트의 데이터가 옮겨지므로, 이 프로세스를 빠르게 개선하는 작업은 복잡하다. 비휘발성이므로 전원이 사라져도 데이터가 보존된다.
- 3차 저장소(Tertiary Storage): 디스크보다도 훨씬 큰 데이터들을 저장하는 하나 혹은 여러개의 머신들이다. 읽기/쓰기 시간이 2차 저장소보다도 오래걸리지만, 바이트 당 비용은 더더욱 저렴하다. 보통 자기 테이프(magnetic tape)나 DVD 같은 광학 디스크(optical disk)를 읽기 장치로 사용한다. 조회에는 몇 초 에서 몇 분이 걸리지만 페타바이트의 용량까지 감당 가능하다. 비휘발성이므로 전원이 사라져도 데이터가 보존된다.
가상 메모리(virtual memory)는 일부는 메인 메모리에, 나머지는 디스크에 디스크 블록(페이지) 단위로 소프트웨어를 저장하는 방법이다. 운영체제와 하드웨어의 상호작용이다. 이것은 데이터베이스가 일반적으로 사용하는 방식은 아니다. DBMS는 스스로 데이터를 관리하기 때문이다. 그러나, 가상 메모리를 이용하여, 메인 메모리에서 데이터를 다루는 것에 대한 관심도가 증가하고 있다.
13.2 디스크
디스크에는 두 가지 움직이는 부품이 있습니다. 디스크 어셈블리와 헤드 어셈블리 입니다. 디스크 어셈블리는 회전하는 디스크들이며, 디스크는 동심원 모양으로 그려진 트랙(track)으로 나뉩니다. 트랙은 다시 sector로 나뉘며, 비자기화된 틈으로 구분됩니다. 헤드 어셈블리는 디스크 헤드를 고정하는 역할을 하며, 헤드 표면에 매우 가깝지만 닿지는 않습니다.
디스크들은 작은 프로세서인 디스크 컨트롤러에 의해 작동한다. 1. 헤드가 어떤 트랙을 가리킬지 2. 트랙의 어떤 섹터를 읽을지 3. 섹터와 메인 메모리 사이의 비트를 전달 4. 디스크 자체의 로컬 버퍼 역할, 이렇게 4가지 역할을 수행한다.
디스크를 읽는 작업은 3단계로 나뉜다. 1. 헤드 어셈블리를 원하는 트랙으로 옮기는 탐색 시간(seek time) 2. 섹터를 헤드 밑으로 이동시키는 회전 지연(rotational latency) 3. 섹터를 읽거나 쓰는 전송 시간(transfer time). 이 때, 전송시간은 전송률(transfer rate)이라는 시간당 읽기/쓰기 하는 블럭의 시간으로 계산된다. HDD의 전송률은 200MB/sec, SSD의 전송률은 5~6GB/sec 수준이다. 이 세 시간을 합친 시간을 디스크 접근 시간(disk access time)이라고 부른다.
13.3 2차 저장소로의 접근시간 개선
디스크 접근시간이 보통 10밀리초 정도라고 해서, 10밀리초마다 정보를 받아볼 수 있는것은 아니다. 이 주기를 앞당기는 기술을 소개한다. 디스크가 하나밖에 없어서, 모든 요청이 10밀리초 이상 걸리는 상황은 스케쥴링 지연(scheduling latency)가 무한대인 상황이다. 우리는 대역폭(throughput)을 늘리기 위해, 아래의 기술들을 사용할 수 있다.
- 같이 접근되는 데이터들을 같은 디스크에 저장하여 탐색 시간과 회전 지연을 줄인다.
- 데이터들을 하나의 큰 디스크가 아니라, 작은 여러개의 디스크에 분리한다. 여러개의 헤드 어셈블리가 독립적으로 접근하여 시간당 접근 블록 수를 늘릴 수 있다.
- 데이터를 여러 디스크에 복제한다. 디스크에 문제가 생겼을 때에도, 데이터를 보호할 뿐만 아니라, 여러 블럭에 동시에 접근할 수 있게 해준다.
- 디스크-스케쥴링 알고리즘을 이용하여, 읽거나 쓸 블럭의 순서를 조정한다.
- 나중에 쓰일 데이터를 미리 메인메모리에 가져다둔다.
그래서 디스크에는 보통 4KB 단위로, 데이터들을 한꺼번에 읽는다. 이 데이터들이 랜덤하게 디스크에 배치된 Random I/O가 아니라, 연속적으로 배치된 Sequential I/O이기 때문에, 매 블럭마다 탐색 시간과 회전 지연을 소모하지 않고, 4KB 당 한번씩만 소모할 수 있다.
버퍼(캐시)를 이용해서, 전체 실행시간을 개선할 수도 있다. 핵심은 디스크 읽기와 버퍼에서 실행하기 작업을 독립된 작업으로 보는 것이다. 첫번째 블럭의 데이터를 읽고, 실행하고, 다음 블럭을 읽고, 실행하고.. 를 반복하는 single buffering technique보다, 첫번째 블럭의 데이터를 실행하는 동안 두번째 블럭의 데이터를 읽기를 병렬적으로 동시에 실행하는 double buffering technique는 더 빠르다.
13.4 디스크 실패
디스크 실패(Disk Failure)는 여러가지 이유로 발생한다.
- 가장 흔한 실패는 간헐적 실패(intermittent failure)이다. 읽기나 쓰기 시도가 실패해도, 다시 시도하면 성공 할 수 있다.
- 심각한 실패는 비트의 영구적인 손상이 일어나는 것이다. 몇 번을 다시 시도해도, 읽기를 성공할 수 없기 때문이다. 이것을 미디어 부패(media decay)라고 부른다.
- 쓰기 실패(write failure)는 쓰기를 시도할때 쓰기를 성공하지도 못하고, 이전에 쓴 섹터를 검색할 수도 없는 경우이다.
- 가장 심각한 실패는 디스크 충돌(disk crash)이다. 모든 디스크가 영구적으로 갑자기 읽을수 없게 된 경우이다.
이 실패들을 대비한 테크닉들이 있다. 간헐적 실패는 패리티체크(parity check)를 통해 보완한다. 미디어 부패와 쓰기 실패에 대비하여 안정적인 저장(stable storage) 전략을 사용할 수도 있다. 우리는 다음 내용에서, 디스크 충돌에 대비하는 RAID(Redundant Arrays of Independent) 전략에 대해 알아본다.
RAID는 데이터들을 여러 디스크에 나눠 저장하는 방법이다. 가장 기본적인 RAID level 0 (=RAID 0)이 그렇다. 디스크들이 병렬적으로 동작할 수 있어서, 하나의 디스크일때보다 읽기/쓰기 모두 빠르지만, 디스크 충돌에 대응이 불가능하다.
디스크 충돌에 대비하는 가장 쉬운 방법은, 디스크의 데이터를 복제하여, 디스크가 고장나도 다시 데이터를 복구할 수 있도록 하는 것이다. 이 것을 RAID level 1(=RAID 1)이라고 한다. 실패네 내성이 있지만, 데이터 디스크 수만큼 중복 디스크가 필요한 단점이 있다.
RAID 4는 데이터 디스크 2개 이상과 패리티 디스크 하나로 구성된다. 데이터들은 데이터 디스크들에 저장하되, 쓰기 작업을 할때마다 패리티 디스크에 오류 검출/데이터 복구에 필요한 패리티 비트들을 쓴다. 데이터 디스크 하나가 고장나도, 패리티 디스크 하나만으로 복원이 가능하지만, 매 쓰기 작업마다 패리티 디스크 쓰기 작업을 해야해서 병목이 생긴다.
RAID 5는 데이터 디스크를 3개 이상 두고, 패리티 정보를 각 디스크에 나눠서 저장하는 것이다. RAID 4의 패리티 쓰기 병목 문제를 해결하지만, 두 개 이상의 디스크 충돌에 대응이 불가능하다.
RAID 10은 RAID 1과 0을 합한 전략이다. 최소 4개 이상의 디스크가 필요하다. RAID 0처럼 2개 이상의 디스크에 데이터를 나눠 저장하고, 각 디스크의 미러 디스크를 만드는 것이다. 그래서, 전체 디스크는 짝수개가 된다. 고성능/고안전성을 모두 확보하지만, 비싸다.
13.5 디스크의 데이터 정렬
이제 디스크가 데이터베이스를 저장하는 방식에 대해 알아본다. 튜플이나 객체는 레코드(record)라고 표현되며, 레코드는 디스크 블럭 내에 연속된 바이트로 저장된다. 이런 정렬 방식을 행-기반 레이아웃(row-oriented layout)이라 한다.
가장 단순한 형태의 레코드는 고정 길이 필드(fixed-length field)로 구성된다. 필드는 튜플의 속성을 의미한다. 대부분의 시스템은 4나 8의 배수의 메모리 주소에서 값을 읽기 시작해야 효율적이므로, 각 필드들은 낭비하는 공간이 생기더라도 4/8의 배수번째 메모리에 저장된다. 어차피 데이터의 조작은 메인 메모리로 가져와서 일어나기 때문에, 2차 저장소인 디스크에서는 접근을 효율적으로 하는것이 가장 중요하다.
레코드는 헤더를 포함한다. 헤더는 레코드 자체에 대한 정보를 저장하는 고정된 길이의 영역이다. 4가지 정보를 담는다.
- 데이터스키마를 가리키는 포인터
- 레코드의 길이
- 레코드가 마지막으로 읽기/쓰기된 타임스탬프(트랜잭션 구현에 중요)
- 필드에 대한 포인터
여러개의 레코드들은 다시 블럭에 모인다. 블럭의 크기 또한 고정되어 있으므로, 레코드들을 저장하고 남는 공간은 버려진다. 또, 블럭은 블럭 헤더를 자체로 갖는다. 블럭 헤더에는 또 5가지 정보가 담긴다. 여기서 네트워크는 블럭들이 모여 구성하는 개념으로, 인덱스의 구현에 사용된다.
- 네트워크 내 다른 블럭들과의 연결 정보
- 네트워크에서 블록의 역할
- 릴레이션 정보
- 디렉토리 정보
- 타임스탬프
13.6 블럭과 레코드 주소 표현
현대 데이터베이스에서는 포인터, 즉 주소값이 레코드에 들어가는 경우가 많다. 포인터는 블럭이나 레코드의 주소를 가리킨다.
블럭과 레코드의 주소는 두 가지로 표현될 수 있다. 첫번째는 물리 주소(physical address)로, 데이터가 있는 호스트, 디스크 id, 실린더 넘버, 트랙, 블럭, 오프셋 등의 구체적으로 데이터가 어딨는지를 나타낸다. 마치 “서울시 강남구 테헤란로 123, 5층 502호” 같은 집주소같다. 반면, 두번째 논리주소(logical address)는 “20180419”처럼 학번같은 개념이다. 이 학번을 가진 학생이 앉은 자리를 찾으려면 맵 테이플(Map table)을 참조하여 실제 물리 주소로 변환하는 과정을 거쳐야한다. 논리주소는 왜 필요한가? 물리주소는 매우 길고 복잡하지만, 논리주소는 간단하다. 그리고, 레코드들은 이동되거나 삭제될 수 있는데, 이 때 테이블의 내용을 수정하는 것이 포인터들을 수정하는것보다 쉽기 때문이다.
물리 주소/논리 주소와 헷갈리기 좋은 데이터베이스 주소/메모리 주소의 개념이 있다. 데이터가 아직 메모리에 로딩되지 않았다면, 데이터는 데이터베이스 주소로 접근해야한다. 하지만, 데이터가 메모리에 로딩되었다면 데이터베이스 주소와 메모리 주소 모두 접근 가능한 주소이다. 앞서 따진 물리 주소/논리 주소는 데이터베이스의 주소를 표현하기 위한 방법이다.
CPU 입장에서 포인터를 참조할때 데이터베이스 주소를 참조하는 것보다는, 메모리 주소를 참조하는 것이 빠르다. 그래서, 데이터베이스 주소를 메모리 주소로 변환할 수 있도록 매핑해둔 값을 저장하는 번역 테이블(Translation table)이 필요하다. 이것을 포인터 스위즐링(pointer swizzling)이라 한다.
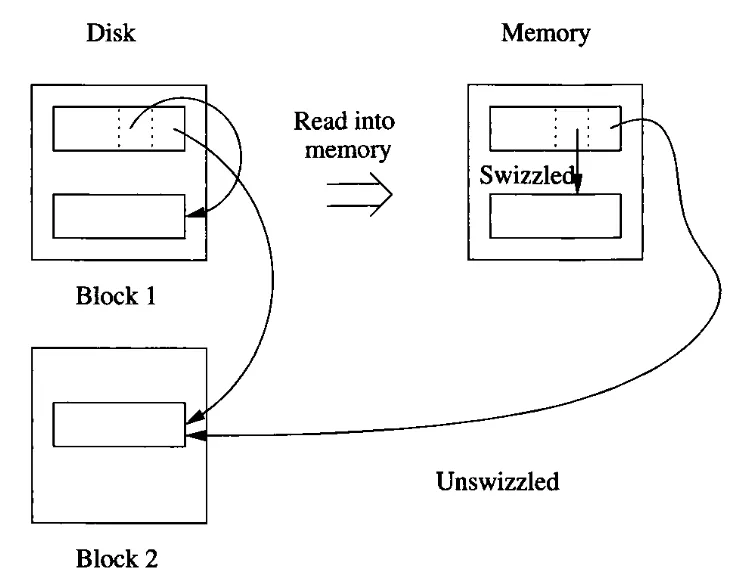
위 그림에서, 블럭1의 첫번째 레코드는 두개의 포인터를 갖고 있다. 이 레코드가 메모리에 올라갈 때, 포인터의 주소는 그대로 데이터베이스 주소를 갖는 것이 아니라, 메모리 주소를 가리킬수 있도록 스위즐(swizzle)되었다. 이때 메모리에 따라 로딩된 레코드를 고정(pinned)되었다고 한다. 번역 테이블에 새로운 행이 추가된 것이다. 반면, 블럭2는 아직 메모리에 올라가지 않았기 때문에 스위즐 되지 못했다. 나중에 블럭2가 올라갈 시점에 다시 그 포인터를 스위즐할지말지 정할 수 있게 되고 그것은 전략의 차이이다. 3가지 전략이 있다.
- 포인터가 메모리에 저장될 때, 참조할 값들을 전부 메모리에 올리고 번역 테이블에 추가하는 자동 스위즐링(automatic swizzling)
- 포인터를 참조하려고 할 때, 그제서야 번역테이블에 매핑을 추가하는 on-demand swizzling
- 하지 않는 no swizzling
No swizzling 전략은 고정된 레코드로 인한 비용 때문에 선택된다. 고정된(Pinned) 블럭은 디스크로 되돌려지는데에 많은 비용이 든다. 원래, 그 블럭을 가리키는 포인터가 가리키는 값이 없어져 외톨이 포인터(dangling pointer)가 되기 때문이다. 고정된 블럭을 디스크로 보낼때는 반드시 역-스위즐(unswizzle)과정을 거쳐야한다.
13.7 가변 길이의 데이터
지금까지는 레코드의 스키마가 고정된 길이만을 가졌지만, 아래의 경우 그렇지 않을 수 있다.
- 255바이트를 할당 해둔 필드가 사실은 50바이트 정도에서 끝난다면, 남는 공간은 여유 공간으로 활용하는 것이 유리할 것이다.
- 다대다 관계를 구현하려면, 반복적으로 포인터 값을 저장하게 된다.
- XML이나 JSON은 길이에 아무런 제약이 없다.
- 오디오, 이미지, 영상 처럼 매우 큰 필드가 있을수도 있다.
이런 필드들을 위해 일단 고정길이의 필드들은 가장 앞쪽에 배치해야 한다. 그리고, 레코드 헤더에 가변 길이의 필드가 시작하는 곳을 가리키는 포인터를 저장한다. 아래 그림에서는 address가 가변길이 필드이다.

혹은, 아예 가변길이의 필드를 별개의 블럭에 둘 수도 있다. 레코드를 탐색하고 이동시키는 비용은 줄지만, 디스크 I/O 횟수가 늘어난다.

XML 같은 가변길이의 레코드는 태그된 필드(tagged fields)들을 이용한다. 태그에는 필드의 이름, 필드의 타입, 필드의 길이 등이 포함된다. 아래 그림은 name과 restaurant owned 필드 정보를 갖는 XML을 저장한 결과이다.

이미지나 오디오 처럼 아주 큰 레코드는 BLOB(Binary, Large OBject)로 불린다. 이 들은 여러개의 블럭에 걸쳐 저장된다(spanned record). 주로 연속적인 블럭에 배치되지만, 영상 재생 등의 이유로 BLOB을 매우 빠르게 검색해야할 수도 있다. 이럴 때는 BLOB을 여러 디스크에 나눠 저장하는 스트라이핑(striping)을 해야한다. 또, 영화의 특정 구간부터 요청 할 경우를 대비해서 적절한 인덱스 구조를 짜는것도 중요하다. 아래는 spanned record 의 모습이다.

'개인 공부' 카테고리의 다른 글
| [데이터베이스 개론] 8. 쿼리 실행(Query Execution) (0) | 2025.06.16 |
|---|---|
| [데이터베이스 개론] 7. 인덱스 구조(Index Structures) (0) | 2025.06.16 |
| [데이터베이스 개론] 5. 데이터베이스의 언어 SQL(The Database Language SQL) (1) | 2025.06.16 |
| [데이터베이스 개론] 4. 대수적/논리적 쿼리 언어(Algebraic and Logical Query Language) (0) | 2025.04.22 |
| [데이터베이스 개론] 3. 고급 데이터베이스 모델(High-Level Database Model) (0) | 2025.04.22 |